谁是当今人工智能世界的最大赢家?毫无疑问,是黄仁勋的英伟达,布局早、技术强,找不到任何竞争对手。躺着就能赚大钱。现在,NVIDIA宣布了最新一代HopperH100计算卡在MLPerfAI测试中创下的新纪录。 HopperH100最早于2022年3月发布,采用GH100GPU内核、台积电4nm工艺、800亿个晶体管和814平方毫米的面积。它集成18432个CUDA核心、576个Tensor核心、60MB二级缓存与六个6144位宽的HBM3/HBM2e高带宽存储器配对,支持第四代NVLink、PCIe5.0总线。相比于ChatGPT等目前普遍使用的A100,H100的理论性能提升了足足6倍。然而,直到最近,H100才开始大规模生产,微软、谷歌和甲骨文等云计算服务也开始批量部署。
HopperH100最早于2022年3月发布,采用GH100GPU内核、台积电4nm工艺、800亿个晶体管和814平方毫米的面积。它集成18432个CUDA核心、576个Tensor核心、60MB二级缓存与六个6144位宽的HBM3/HBM2e高带宽存储器配对,支持第四代NVLink、PCIe5.0总线。相比于ChatGPT等目前普遍使用的A100,H100的理论性能提升了足足6倍。然而,直到最近,H100才开始大规模生产,微软、谷歌和甲骨文等云计算服务也开始批量部署。
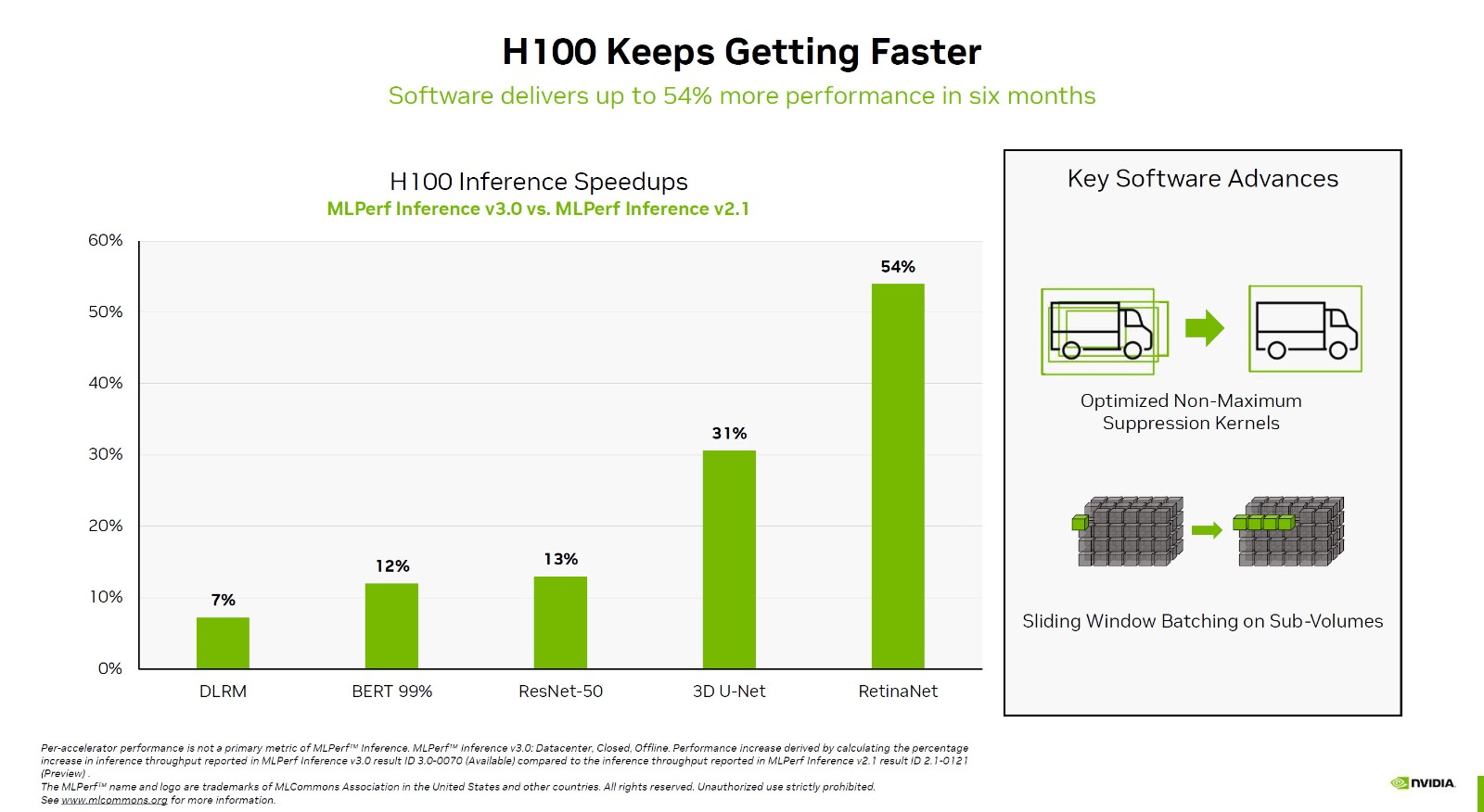 MLPerf推理是测试人工智能推理性能的行业标准,最新版本为v3.0,也是该工具诞生以来的第七次重大更新。与六个月前的2.1版本相比,NVIDIAH100在不同测试项目中的性能提高了7-54%,其中最大的改进是RetinaNet全卷积神经网络测试和3D测试。U-Net医学成像网络测试也可以提高31%。
MLPerf推理是测试人工智能推理性能的行业标准,最新版本为v3.0,也是该工具诞生以来的第七次重大更新。与六个月前的2.1版本相比,NVIDIAH100在不同测试项目中的性能提高了7-54%,其中最大的改进是RetinaNet全卷积神经网络测试和3D测试。U-Net医学成像网络测试也可以提高31%。 对比A100,跨代提升更是惊人,无延迟离线测试的变化幅度少则1.8倍,多则可达4.5倍,延迟服务器测试少则超过1.7倍,多则也能接近4倍。其中,DLRM、BERT训练模型的提升最为显著。英伟达还可耻地列出了英特尔最新的旗舰数据中心处理器Platinum8480+,拥有56核。毕竟,该行业拥有专业知识,这使得通用处理器运行人工智能培训有点困难。糟糕的分数不值得一提,BERT99.9%甚至无法运行,这是NVIDIAH100的最强功能。
对比A100,跨代提升更是惊人,无延迟离线测试的变化幅度少则1.8倍,多则可达4.5倍,延迟服务器测试少则超过1.7倍,多则也能接近4倍。其中,DLRM、BERT训练模型的提升最为显著。英伟达还可耻地列出了英特尔最新的旗舰数据中心处理器Platinum8480+,拥有56核。毕竟,该行业拥有专业知识,这使得通用处理器运行人工智能培训有点困难。糟糕的分数不值得一提,BERT99.9%甚至无法运行,这是NVIDIAH100的最强功能。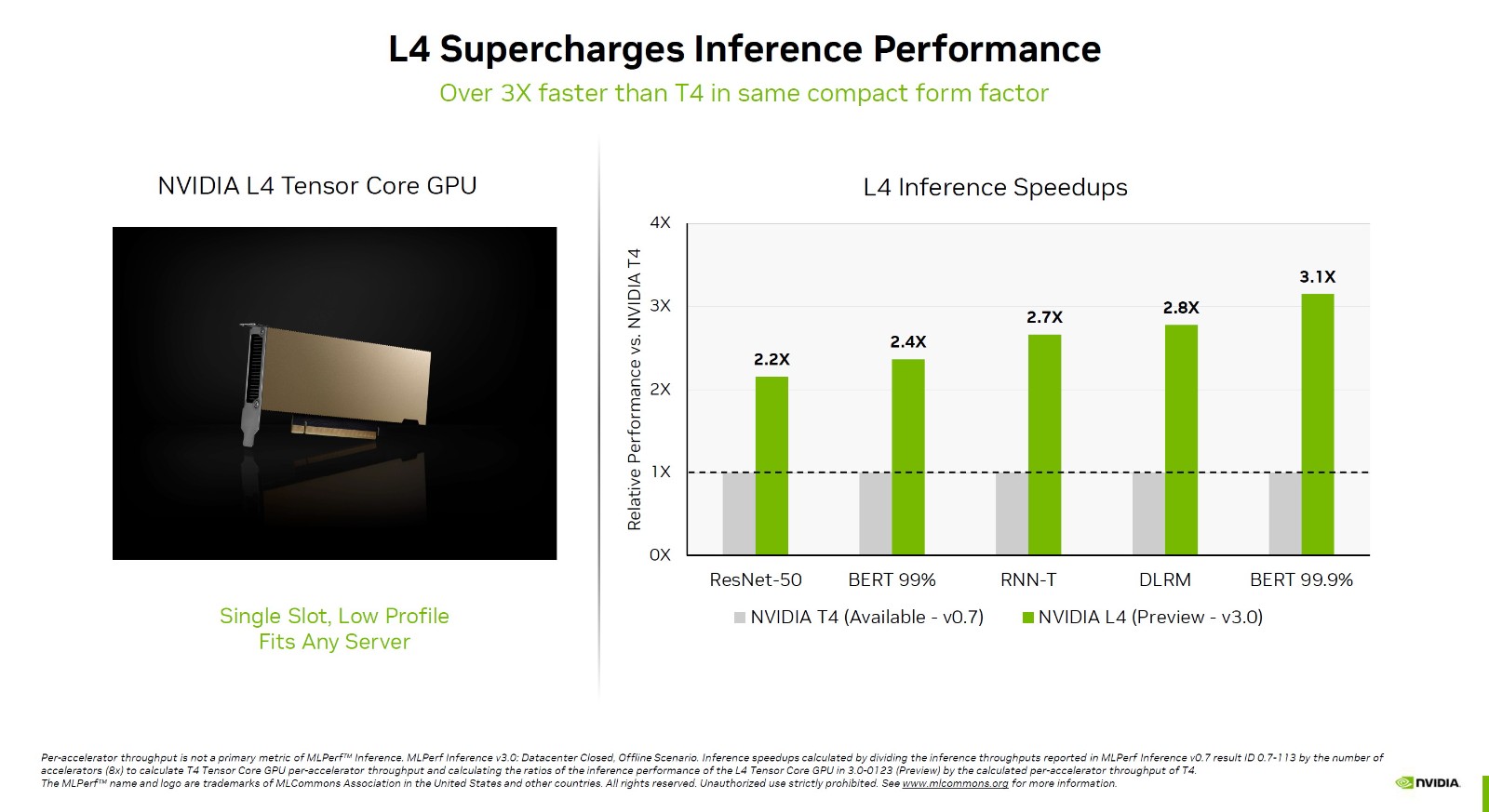 此外,NVIDIA还首次发布了L4GPU性能。它基于最新的Ada架构,只有张量张量核,支持FP8浮点计算。它主要用于人工智能推理,也支持人工智能视频编码加速。对比上代T4,L4的性能可加速2.2-3.1倍之多,最关键的是它功耗只有72W,再加上单槽半高造型设计,可谓小巧彪悍。几乎所有大型云服务提供商都部署了T4,升级到L4只是时间问题,谷歌已经开始内部测试。
此外,NVIDIA还首次发布了L4GPU性能。它基于最新的Ada架构,只有张量张量核,支持FP8浮点计算。它主要用于人工智能推理,也支持人工智能视频编码加速。对比上代T4,L4的性能可加速2.2-3.1倍之多,最关键的是它功耗只有72W,再加上单槽半高造型设计,可谓小巧彪悍。几乎所有大型云服务提供商都部署了T4,升级到L4只是时间问题,谷歌已经开始内部测试。
